
IT 業界では、現在も AI / 機械学習を活用したプロダクト開発に注目が集まっている。サイバーエージェントでは様々な事業で機械学習技術を活用したサービス開発が盛んに行われており、部署を跨いだ技術の共有・活用を狙った基盤技術の開発も活発だ。今回は、データ活用に関わる基盤技術開発を行うデータプロダクトユニット(以下 DPU)とグループ横断のインフラ技術組織である CyberAgent Group Infrastructure Unit(以下 CIU)の Dev Div でそれぞれ機械学習に関する基盤システムの開発に携わる二人のエンジニアに、開発にまつわる話を聞いた。


機械学習モデル管理基盤「Etna」開発の裏側
CIU が開発する ML Platform では、DPU の大内さんが開発した機械学習モデル管理基盤である Etna が採用されています。Etna はもともと ML Platform 向けに開発されたのでしょうか?
大内:いえ、元々 Etna の開発はメディアのデータ活用を支援する組織である Media Data Tech Studio(以下 MDTS)でメディア事業での活用を前提に開発をしていました。MDTS にはデータサイエンティストや機械学習エンジニアが所属しており、様々なサービスに対して推薦や検索、データ分析などのソリューションを提供しています。それぞれが担当サービスに対して機械学習技術での価値提供をする際に、どうしてもモデル開発が属人化してしまうという問題が出てきてしまいます。そのような問題を解決するべく、Etna を開発しました。
モデル開発の属人化という問題は、機械学習モデル開発のプロセスの中でなぜ生じてしまうのでしょうか。
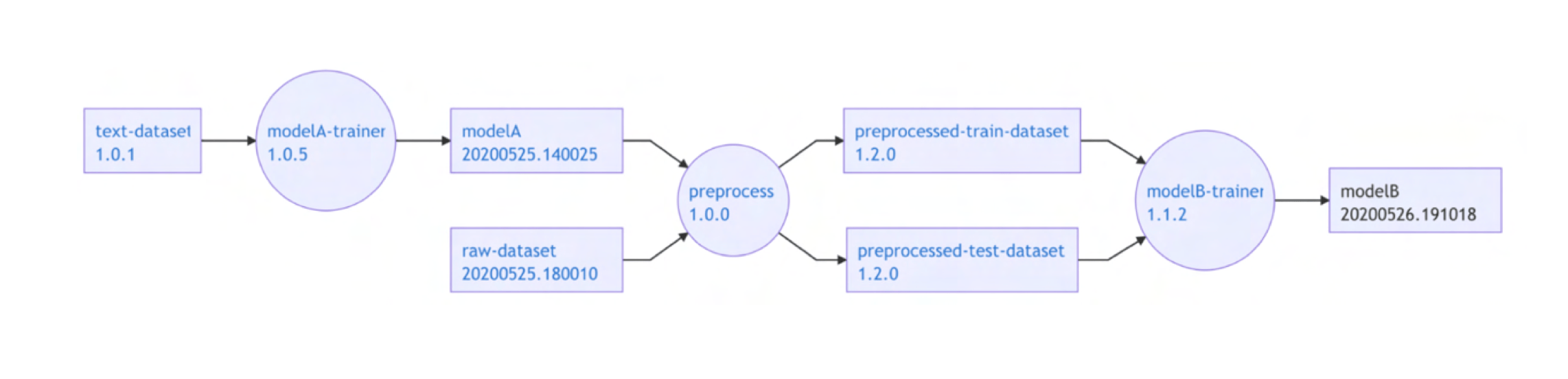
大内:機械学習モデルを作成するまでの業務フローは、機械学習で解決したい問題に沿うようにデータ設計をするところから始まります。その後、そこからデータを抽出・整形し、機械学習アルゴリズムを選択して学習済みモデルを作成、最後に評価を行って当初設定した課題が達成されるかを確認するといった大まかな流れになっています。もし評価の結果が満足いくものでなかった場合には、データ設計を見直したり、データの量や前処理の方法、アルゴリズムを変更したりと試行錯誤的に開発を進めていきます。ここで、システムの安定化やモデルの品質を担保するためには試行錯誤の過程でどのようにデータを加工したのかというデータフローを管理することが重要になってきます。例えば学習済みモデルが意図しない挙動をし、その原因を調査する場合、通常のソフトウェア開発ではソースコードの調査をするだけで十分ですが、機械学習の場合では学習に使ったコードやデータセットの調査も必要になります。さらにデータセットが何らかの処理によって得られたものであった場合、その処理内容に問題がなかったのかを調査する必要も出てきます。しかしこの試行錯誤は機械学習エンジニアが個人で行うことが多く、その管理方法はエンジニア毎、または開発チーム毎に異なっています。これらの情報が適切に管理されていない場合に、モデル開発の属人化の問題が発生します。

Etna ではそのように属人化しがちな、機械学習モデル開発におけるデータフローの管理・可視化を解決するために開発されたと。
大内:はい。データフローの管理がされていないと、学習済みモデルの出力が期待するものでなかった時に、その原因が学習データなのか、学習コードなのか、または学習データを作るまでの過程にあるのか見当をつけにくくなります。また、新しいメンバーが開発に加わった際に、開発の全貌が把握しにくいといった問題も発生する可能性があります。これらのデータフローは mlflowのようなプラットフォームや既存のワークフローエンジンなどで管理可能ですが、「前処理に特定のバージョンを利用した学習済みモデルをデプロイしたい」や「自身の学習済みモデルで提供した特徴量が他モデルで利用されているかを把握したい」といった要求があり、既存のものでは困難であったため内製することを決めました。
現在、どのようなサービスで Etna が導入されているのでしょうか。
大内:ABEMA の動画特徴量解析に利用するモデルや、Ameba ブログのスパム検出に使うモデルの管理 [2]、言語処理基盤に利用するキーワード辞書の管理 [3] など多岐に利用されています。データフローの管理・整理を目的に導入したチームが多かったのですが、導入した副次的な効果として「インターンなどの新しいメンバーが加わった際にプロジェクトの全貌をデータフローを使って説明できて良かった」などのフィードバックがありました。
CIU の ML Platform に Etna を採用した理由
漆田さんは現在 CIU で ML Platform の開発兼 PjM を担当されています。どういった経緯で、ML Platform で Etna を採用するに至ったのでしょうか。
漆田:ML Platform には現在 2 つのサービスがあり、GPU 環境を提供する “GPUaaS” と学習・推論の実行基盤である “AIPlatform” から成り立っています。Etna はこの AI Platform の推論機能で利用されています。 ML Platform ではユーザーからモデルに関する情報(S3 などのパス、バージョン名、その他タグなど)を受け取り、そのモデルを Kubernetes 上にデプロイしてエンドポイントを払い出します。これらのモデル情報を構造的に格納するためのデータベースとして Etna を採用しています。
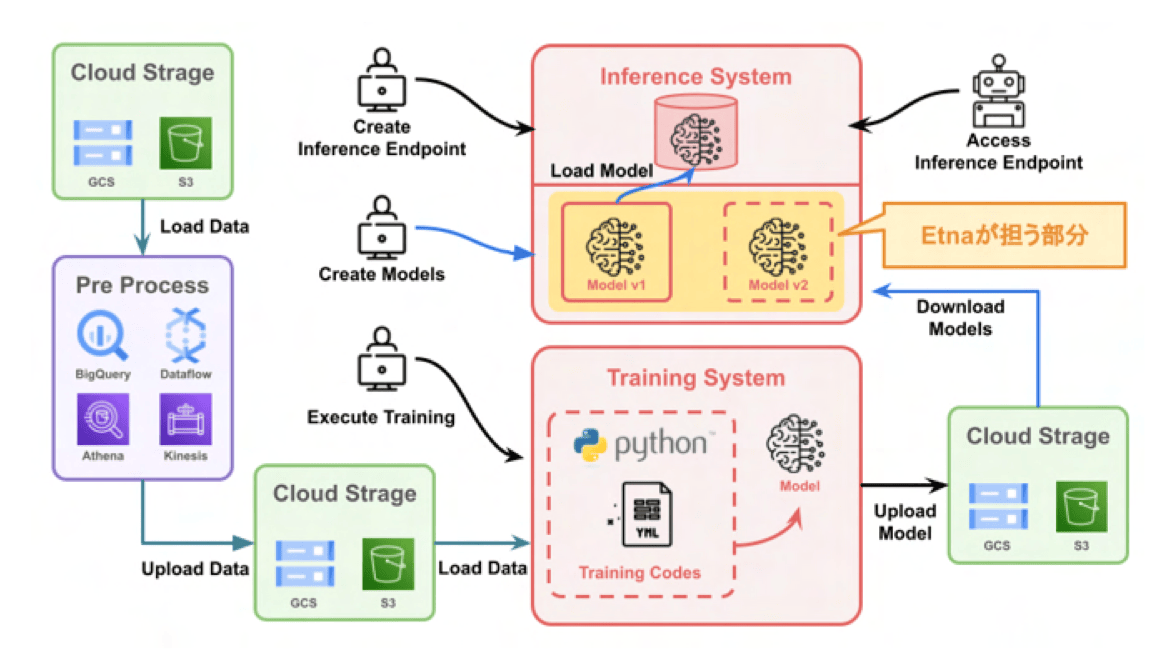
画像2. ML Platformの全体像とEtna
大内:モデルをダウンロードする際にそのモデルが S3、GCS、その他どの場所にあるのかによって問い合わせ方法が変わってしまうのですが、Etna を噛ませることで Etna 側でストレージの違いを吸収してくれるので ML Platform 側はモデルの場所を気にすることなく、Etna に問い合わせるだけで良くなるんです。
漆田:ユーザーがデータストアの場所を意識せずに使えるようになるというのは、大きな利点でしたね。世の中にはいくつかのモデルバージョンストアがありますが、Etna は利用方法や機能がシンプルでわかりやすく組み込みのイメージがすぐに湧いたのと、Kubernetes 上で 1 年間 ( 当時 ) の運用実績があったため選択しました。また、Etna はマルチテナンシー機能を備えているのも良いですね。我々みたいな共通基盤を作る組織はプロダクトごとに環境を分離して提供する必要があるのでこの機能があるのは助かりました。
大内:Etna はもともと様々な部署で使われることを前提に設計しているので、CIU が希望する用途もカバーできていたのは、とても嬉しいですね。Etna を開発するにあたって設計はかなり悩みましたが、こういった形で他部署の要望も吸収できていたので、設計はうまくいっていたのだなと少し安心しています。

社内基盤同士ということで、開発連携上のメリットなどを感じた場面はありましたか?
漆田:社内で距離が近いからこそ、ちょっとした機能追加などを気軽にお願いできるのが良かったですね。ML Platform のメインユーザーは GCS を利用することが多いので、S3に加えて GCS の URI にも対応できるようにお願いしたところ 1 週間ほどで対応されていてとても進めやすかったのを覚えています。
大内:今回の Etna と ML Platform のように、社内の異なる部署で開発された基盤が、「コラボレーションによって事業貢献できる共通基盤」として成長していく、という一つの事例になると嬉しいですよね。
Etna と ML Platform、そして「機械学習基盤の未来」
それぞれのプロダクトの今後の展望などがあれば、ぜひ聞かせてください!
大内: Etna に関して言えば、今後は Etna 単体での取り組みではなく、もう少しスコープを広げて MLOps 基盤全体と Etna をうまく連携させたいと考えています。Etna を利用することでモデルのバージョン管理はもちろん、そのモデルがどのバージョンの学習データを使ったのか、関連する機械学習モデルのバージョンは何であるのかといったメタデータを管理することが可能になります。こういったメタデータは現在のところユーザーに登録してもらっているのですが、MLOps 基盤の実験環境やデータ基盤と連携することでこれらのメタデータを自動的に抽出し、ユーザーの負荷低下が見込めます。また運用の観点からも、モデル自体と学習データを紐づけて管理しているので、サービングしたモデルに与えられる実際の入力と、学習時のデータの入力の分布を比較することで、データドリフト * の検知にメタデータが利用できます。これによってモデルの品質低下、ひいては機械学習システムの品質低下の防止に役立てることができると思っています。
* モデル学習時からのデータ分布の変化に伴ってモデルの性能が低下してしまうこと

漆田: ML Platform でも Etna と同じように連携に点を置いていて、特に本基盤内の各サービス間連携に力を入れていく予定です。先程紹介した通り AI Platform には学習と推論の機能があるのですが、現状それぞれ独立したものになっています。このままではモデルを学習してからデプロイするまでの作業が面倒になってしまうので、このフローを一連の作業として実現するためにパイプライン機能の実装を考えています。このあたりは Etna にも近しい機能があったと思うのでそれを使うかアイデアをいただくなどして今後もやりとりを続けていきたいです。また、パブリッククラウドからでも連携できるように AI Platform を扱う Python ライブラリの用意なども考えています。
機械学習のプロジェクトは、機械学習モデルの作成にスポットが当たりがちですが、同時にそれを支える機械学習システム全体を効果的に開発・配置し、洗練させていくことも非常に重要だと言われますよね。お二人のコメントから、機械学習プロジェクト全体を支える基盤として、それぞれのプロダクトを成長させていきたいという思いを感じます。
漆田:私の所属する CIU は社内向けプライベートクラウドの開発・運用も行っており、サイバーエージェントグループをインフラ技術を軸に支えるというミッションがあります。ML Platform もそのミッションを意識し、インフラとして GPU リソースの増強も常に考えています。モデルの学習に必要な計算リソースは時が経つにつれて非常に膨大になっています。そして AI を導入しようとする社内プロダクトも次々と増えており、そういった点でも GPU の需要は増えています。オンプレはコスト、リソース量、最新 GPU 導入速度の観点から優位性があるため社内の ML 系開発者の方々が不便しないようにソフトウェア・ハードウェア共に基盤を整えていきたいですね。
大内:私が所属する DPU に関しては、機械学習に関わる「似たようなタスクを自動化する」という目標があります。機械学習モデルで達成したい目標は開発プロジェクトごとに変わってきますが、作成した機械学習モデルをバージョン管理することはどのようなプロジェクトであっても必要になりますし、こういった似たようなタスクを基盤で吸収することで、機械学習エンジニアの負荷を下げていきたいです。更に発展させて、運用に必要なメタデータを自動で取得・管理し、適切にユーザーにフィードバックすることで機械学習システム全体の品質を担保できるような基盤として Etna が利用できるようにしていきたいですね。
今後の両プロダクトの成長に期待しています。ありがとうございました!
参考資料
1. https://mlflow.org
2. 秋葉原ラボ技術報告
https://d2utiq8et4vl56.cloudfront.net/files/topics/24075_ext_22_0.pdf?v=1574233973
3. AI/Data Technology Map
https://d2utiq8et4vl56.cloudfront.net/files/user/pdf/techinfo/AIDataTechnologyMap_210520.pdf?v=1621566300