
即時性の高いデータ活用を支援する
SQLライクなクエリ言語による宣言的なストリーム処理基盤
1日あたりのイベント受信数(全クラスタ合計) : 約18億/日
1日あたりのクエリ数(全クラスタ合計) : 約28億/日
登録されているテーブルの数(全クラスタ合計) : 133
Zeroは、即時性の高いデータの活用を容易にすることを目的として開発された宣言的なストリーム処理システムです。欲しいデータの定義をSQLに近いクエリ言語を用いて記述するだけで、ストリーム処理により逐次更新される最新のデータがAPIから低いレイテンシで取得できます。
各種サービスでのコンテンツ推薦、トレンド検知、速報値のレポーティング、また、広告配信での配信制御などの用途で幅広く活用されています。
Member
Software Engineer : 開発・運用担当
使用している主な技術
Apache HBase, Google Cloud Bigtable, Amazon DynamoDB, Apache Kafka, Apache Flume, Google Cloud Pub/Sub, Amazon Kinesis Data Streams, Redis, MySQL, Prometheus, Kubernetes, Apache ZooKeeper, Java, Go, C++, etc.
システムの概要
解決したい課題/ ユースケース
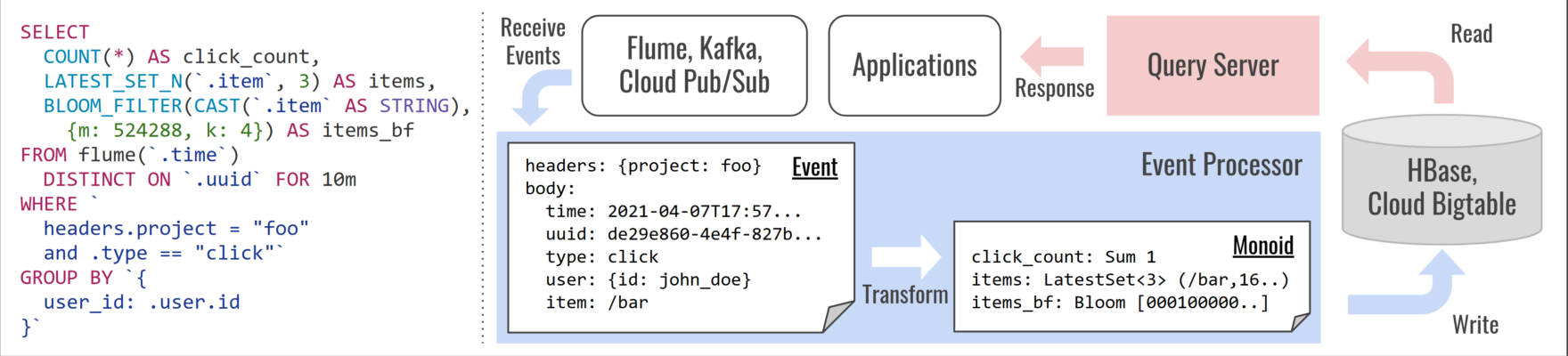
Zeroは主に、イベントの処理を行うプロセッサ側と、APIを提供するサーバー側、の 2 つの処理にわけられます。プロセッサ側では、Apache Kafka などからイベントを受け取り、事前に定義したクエリを元に、必要なデータを抽出・集約し、Apache HBaseなどのデータストアに書き込みます。サーバー側では、API からリクエストを受け取り、データストアやキャッシュを参照して結果を返却します。プロセッサ側ではイベントの集約処理も行いますが、集約関数としては、数値を加算するだけの単純な count(), sum()のような単純なもの、latest(), latest_set_n() のようなイベント時刻順による最新値を取得するようなもの、また、bloom_filter() のような確率的データ構造を扱うものなどが実装されています。このような集約関数の処理は、可換性のあるモノイド(ストリームデータの配送順序は保証されていないことが多く、最終的に同じクエリ結果を得るためにも可換性が必要)の演算として考えると都合がよいため、内部やデータストア上では可換モノイドとして抽象化して扱っています。
「AWA」での導入事例
解決したい課題/ ユースケース
音楽ストリーミングサービス「AWA」には、急に多く聴かれるようになった楽曲を自動で選曲する「リアルタイム急上昇楽曲 トップ100」というプレイリストが実装されています。この機能では、楽曲ごとの一定期間ごとの再生回数をリアルタイムに集計する部分でZeroを使用しています。これだけでは再生回数が分かるだけですが、別途、急上昇スコアを計算するトレンドシステムを組み合わせることで「リアルタイム急上昇楽曲」として動作しています。
また、一般的に推薦システムでは、新しいコンテンツの発見に繋げるために、ユーザがまだ触れていないものを推薦したい場合があります。ZeroのBloomFilter機能を使用することで、実際の再生データを記録することなくハッシュ化された小さなデータ量のビット列のみから、ある楽曲をすでに視聴している可能性があるかどうかを高速に知ることができます。この機能は、AWAでのニーズをもとに実装され、推薦機能の一部で利用されています。
このように、Zero自体にはシンプルな機能しかありませんが、様々な機能を実現するための部品として他のコンポーネントと組み合わせて使用され、ストリーム処理を新規開発することなく、クエリの記述のみですぐに最新のデータを利用できるようになることから、即時性の高いデータが必要なアプリケーションを開発するために活用されています。
※アルゴリズムの詳細は将来的に変更される可能性があります。
関連リンク
ー
サービス紹介
-

TiDB
1テーブルの行数 : 約5億行2025年のダウンタイム : 0 minクエリ実行数 : 約5千万/day Ti…
-

C4
登録スキーマ数(≒テーブル数) : 731平均イベント数 : 16.5 億イベント/日累計データ量 : 206…
-

wurfrahmen
Kubernetesで簡単にワークフロー管理を実現 導入サービス数 : 5実行されるワークフロー数 : 約4…